我们生活中最常见的音频压缩算法就是我们的mp3,早些年大家都喜欢下载这种类型的音乐,一首歌3-4M字节,空间占用少,毕竟那时候的MP播放器还是256M或者512M的时候。

单片机中的音频播放
音频播放在小型单片机系统中也会经常用到,最早我做的地铁广播系统中就是用的单片机播放的音频。这人中音频播放大体上有两种方式,一种是使用vs1003这样的外置模组来进行数据解码,另一种就是单片机自己解码。
单片机的运算能力有限,因此靠单片机来计算MP3还是一项比较沉重的工作,所以,一般的小型系统中,我们往往不适用MP3格式的音频,二十直接播放wav格式的音频。
说白了,wav格式就是纯音频数据存储,没有进行过压缩的,也就意味这不需要解码,这样一来单片机只需要将两通道的音频数据丢到IIS缓存区即可。
没有IIS外设的怎么办?那就用DAC,12bit的DAC播放个音频指示或人声完全没问题。
什么? 连DAC也没有,让我想想。。。
那就用PWM吧,配置一个PWM,占空比可调,具备10bit可调范围的PWM,硬件方面,就在引脚上加一个RC滤波,一样可以播放好听的效果音乐。
PWM也没有吗?
那也没关系,有IO口就能搞,不过今天重点不是说这个,重点是想说,这个wav文件还是有点大,我们需要对他做一些压缩算法来存储到我们可怜的Flash空间中。
音频格式初探
ADPCM算法是一种针对16bit的声音波形数据的一种有损的压缩算法,他将声音流中每次采样的16bit数据,转变成4bit来存储,所以它的压缩比为1:4。
想想,音频文件可以节省4倍,这得省好几毛钱了,而且这种压缩算法简单,51单片机就能轻松应对,因此这中压缩算法是一种地空间消耗,高质量音频获得的好途径。
ADPCM主要是针对连续的波形数据,它保存的是波形的变化情况,以达到描述整个波形的目的。
先科普一下音频信号存储的知识。
一般我们在PC机的游戏中或者公交车报站器中使用到的声音,都是提前录制好的,这种录制就是一种模拟转数字的过程,因此这里面涉及到了香浓的采样定理。
我们一般对于音频的采样率会设置在44.1Khz,根据香浓定律,我们可以还原出22KHz的声音,这已经是大多数人耳朵能分辨的频率的上限了。也有异能人士可以听到更高,或者跟老柴我一样最高只能分辨到16KHz,因人而异吧。
知道了采样频率,我们再看一下对于一个升压,我们需要将他量化存储,到底需要多少个bit才能表示真个声音中的大大小小的赋值呢?这个一般我们音乐是按照16bit处理的,也不是想多高就能多高,还得看采样的ADC强不强。
有了一个一个的升压赋值和采样频率,只要我们按照频率把赋值送给扬声器,我们就可以听到录制的音乐了。
在wav中,数据的存储非常的简单粗暴,就一个挨着一个的放,所以我们定好时间挨着个的取数据就可以了。
其实,8bit的采样深度就足够人耳享用的了,比如win95的开机音乐。 16bit就已经算是高音质了,现在很多游戏中采用16bit,单片机系统中,比如报站什么的8bit足够了。
有了声音的基本存储,我们来看看如何压缩。
ADPCM算法
因为声音一般是连续的,也就是频率足够快的情况下,前后两个采样值之间的差异会比较小。
我们就利用这个特性来对数据进行压缩,也就是对两次采样值的差再做一次量化,由于这个差值比较小,因此我们可以使用更少的bit来存储,这样就实现了压缩的结果。
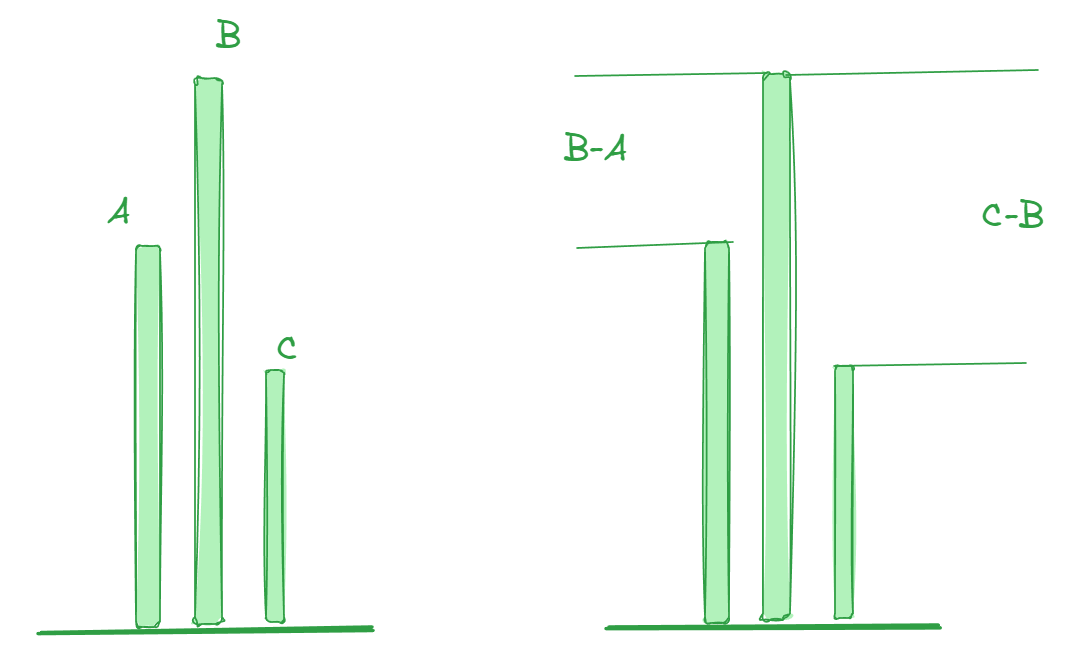
如上图所示,直接存储的方式中,我们存储的数据是ABC三个16bit的数据,如果按照ADPCM压缩算法,我们存储的将是相对值,也就是B-A,C-B这样的更小的值,当然重新播放的时候,我们要有一个初值。
其实初值就是0,声音怎么也得是慢慢变大的,不然喇叭受得了,你耳朵也受不了。
接下来,我们看如何二次量化。
如果我们想压缩为4bit,那么也就是一共16个等级,你可以平均分配,但显然这样做很不明智,有大神发明了两种重新量化的定律,叫A Law和u Law。其实就是非线性量化,至于做成什么样的非线性,这得研究人耳朵对音乐的敏感性了,不在我们讨论范围内。
我们来看一个图,大致了解下两个Law的不同。
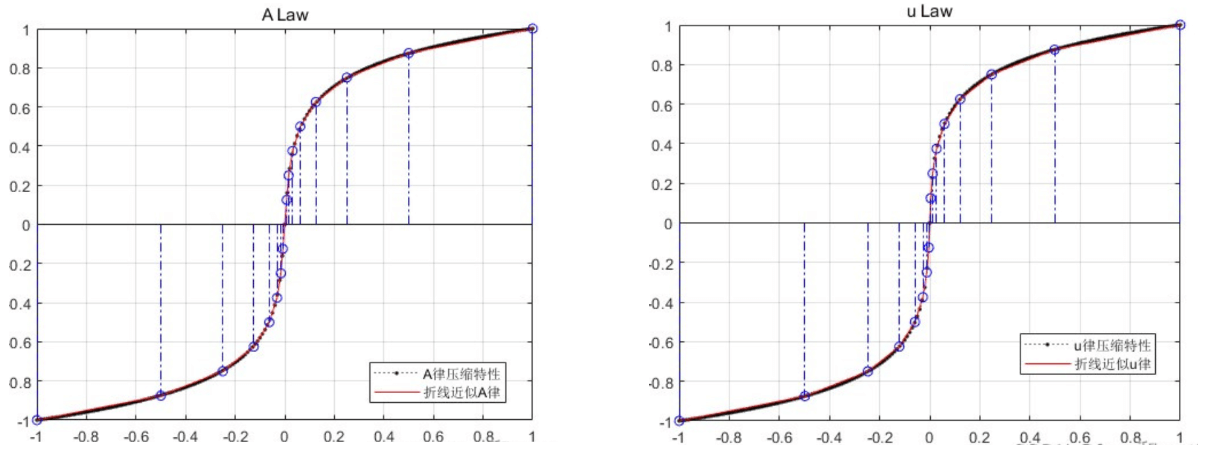
乍一看其实没太大区别,所以这种非线性量化其实也挺随意的。
由于信号量噪比的不恒定而影响信号质量,为了对不同的信号强度保持信号量噪比恒定,在理论上要求压缩特性为对数特性。
为了使信号量噪比保持恒定,引入A压缩律与μ压缩律以及相应的近似算法-13折线法和15折线法。 一般来说,U律的15折线比A律的13折线,各个段落的斜率都相差2倍,所以小信号的信号量噪比也比A律大一倍,但是对于大信号来说,u律比a律差。
无论哪个折线法,到我们写程序的时候都变成了一个数组而已,我们就根据采样值的差值落到那个区间内来定义他的编码值。
最后我附上代码,大家可以琢磨一下,需要详细讨论可以后台私我,也可以加入我的星球讨论。
代码
压缩:
int index = 0, prev_sample = 0;
while (还有数据要处理) {
cur_sample = getnextsample(); // 得到当前的采样数据
delta = cur_sample-prev_sample; // 计算出和上一个的增量
if(delta < 0) delta=-delta,sb=8;
else sb=0; // sb 保存的是符号位
code = 4*delta/step_table[index]; // 根据 steptable[] 得到一个 0~7 的值
if (code > 7) code = 7; // 它描述了声音强度的变化量
index += index_adjust[code]; // 根据声音强度调整下次取steptable 的序号
if(index < 0) index=0; // 便于下次得到更精确的变化量的描述
else if (index > 88) index = 88;
prev_sample = cur_sample;
outputode(code|sb); // 加上符号位保存起来
}
解压缩
int index = 0, cur_sample = 0; //信号从0开始,否则耳朵不保
while (还有数据要处理) {
code=getnextcode(); // 得到下一个数据
if ((code & 8) != 0) sb=1
else sb=0;
code &= 7; // 将 code 分离为数据和符号
delta=(step_table[index]*code) /4 + step_table[index] / 8;
// 后面加的一项是为了减少误差
if (sb == 1) delta =- delta;
cur_Sample += delta; // 计算出当前的波形数据
if (cur_sample > 32767) cur_sample = 32767;
else if (cur_sample < -32768) cur_sample = -32768;
output_sample(cur_sample);
index += index_adjust[code];
if (index < 0) index = 0;
if (index > 88) index = 88;
}
附表
int index_adjust[8] = {-1,-1,-1,-1,2,4,6,8};
int step_table[89] = { 7, 8, 9, 10, 11, 12, 13, 14, 16, 17, 19, 21, 23, 25, 28, 31, 34, 37, 41, 45, 50, 55, 60, 66, 73, 80, 88, 97, 107, 118, 130, 143, 157, 173, 190, 209, 230, 253, 279, 307, 337, 371, 408, 449, 494, 544, 598, 658, 724, 796, 876, 963, 1060, 1166, 1282, 1411, 1552, 1707, 1878, 2066, 2272, 2499, 2749, 3024, 3327, 3660, 4026, 4428, 4871, 5358, 5894, 6484, 7132, 7845, 8630, 9493, 10442, 11487, 12635, 13899, 15289, 16818, 18500, 20350, 22385, 24623, 27086, 29794, 32767 };
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
没有相关内容!

暂无评论...