
新晋C语言爱好者,或多或少的都会遇到烫烫烫,屯屯屯等乱码,一般是在调试代码打印log的时候出现,初学C语言编程的时候,一不小心就会出现一堆的烫烫烫。

这里的烫烫烫主要是数组越界了,或者打印了一些野指针。因为window的编码格式里面,对于未初始化的变量会默认的设置为0xCC。而 CC 在Unicode的编码中就是表示中文的“烫”,所以就是很多“烫”字。
我们在使用stm32这一类的单片机开发的时候,就没有遇到过烫烫烫,这是因为我们的未初始化变量会被启动程序清除为0 。
但是,当我们编码和打印log时依然会出现各种编码问题导致的乱码,比如下面这样
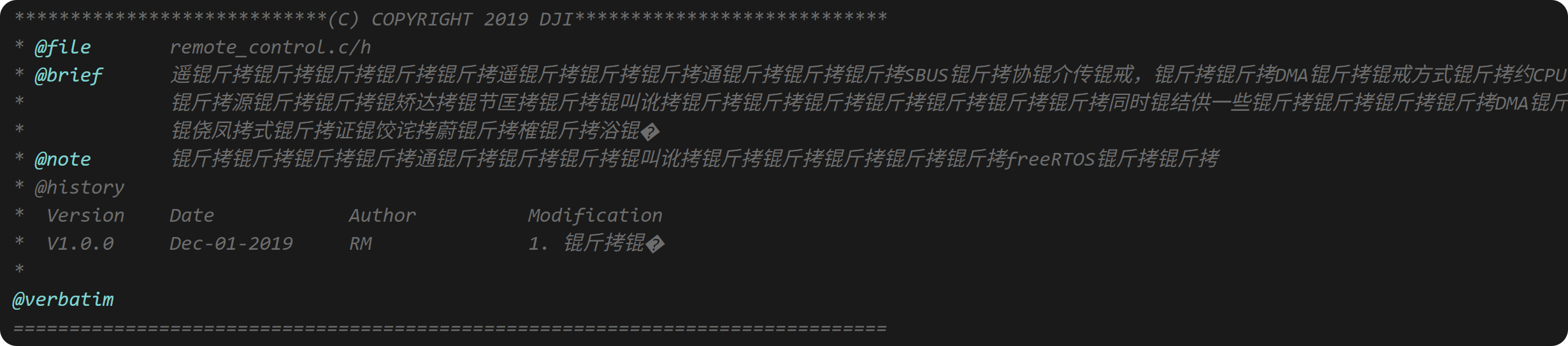
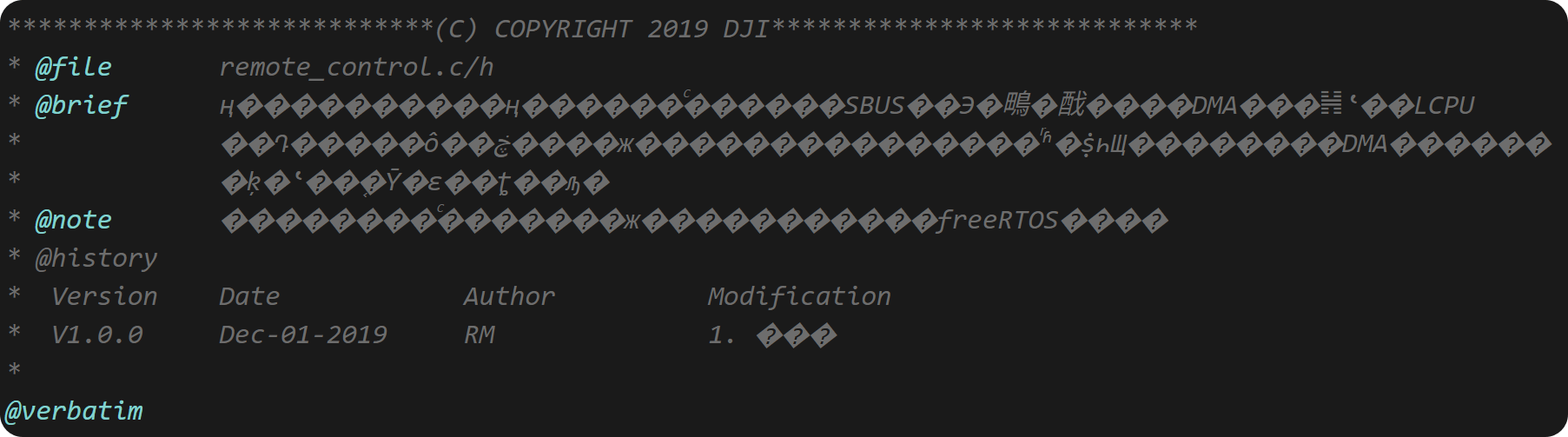
这里的问题主要是源文件编码的问题,比如keil目前的默认编码格式为ANSI,vscode的默认编码格式为UTF-8。 这样当我们在不同的编辑器之间切换的时候,就会出现各种乱码的情况。

先看看那些奇奇怪怪的乱码怎么来的
锟斤拷乱码:
锟斤拷乱码源于GBK字符集和Unicode字符集之间的转换问题。
Unicode和老编码体系的转化过程中,肯定有一些字,用Unicode是没法表示的,Unicode官方用了一个占位符来表示这些文字,这就是:U+FFFD REPLACEMENT CHARACTER。
那么U+FFFD的UTF-8编码出来,恰好是 ‘\xef\xbf\xbd’。如果这个’\xef\xbf\xbd’,重复多次,例如 ‘\xef\xbf\xbd\xef\xbf\xbd’,然后放到GBK/CP936/GB2312/GB18030的环境中显示的话,一个汉字2个字节,最终的结果就是:锟斤拷——锟(0xEFBF),斤(0xBDEF),拷(0xBFBD)。
烫烫烫乱码:
在windows平台下,微软的编译器(也就是vc带的那个)在 Debug 模式下,会把未初始化的栈内存全部填成 0xCC,用字符串来看就是”烫烫烫烫烫烫烫”,未初始化的堆内存全部填成0xCD,字符串看就是“屯屯屯屯屯屯屯屯”。也就是说出现了烫烫烫,赶紧看看初始化和越界问题。
锘锘锘乱码
BOM 是 Byte Order Mark 的缩写。是UTF编码方案里用于标识编码的标准标记,在UTF-16里本来是FF FE,变成UTF-8就成了EF BB BF。这个标记是可选的,因为UTF8字节没有顺序,所以它可以被用来检测一个字节流是否是UTF-8编码的。
锘 → EFBB
匡 → BFEF
豢 → BBBF
出现这个问题肯定是你写网页的时候用了记事本 ,记事本在保存文件的时候把原本文件的编码改了。
记事本会默认保存为UTF-8的编码,而如果你原本网页是GBK编码的,就会出现乱码。
BOM就是把一个Unicode保留字符U+FEFF,按照文件存储者的编码方式编码后,塞到文件内容的最前边。这样用不同的Unicode编码去解析文件头,就可以得知文件的编码方式和大小端顺序。结果就是文件头部多出来了两三个字节。
任何时候都采用无BOM的UTF-8编码的Unicode,绝对是一个引发麻烦最少的最实用策略。UTF-8是Unicode的最佳实践,没有之一。
值得注意的是,微软经常做出非要DOM不可的行为,最典型的例子就是那个记事本(存盘就加DOM)。所以任何时候,都千万别偷懒用记事本编辑。Notepad++是Windows下的不二之选。
手持两把锟斤拷,口中疾呼烫烫烫。脚踏千朵屯屯屯,笑看万物锘锘锘
为什么会有这么多字符编码格式?
预备知识:
字符:在计算机和电信技术中,一个字符是一个单位的字形、类字形单位或符号的基本信息。即一个字符可以是一个中文汉字、一个英文字母、一个阿拉伯数字、一个标点符号等。
字符集:多个字符的集合。例如GB2312是中国国家标准的简体中文字符集,GB2312收录简化汉字(6763个)及一般符号、序号、数字、拉丁字母、日文假名、希腊字母、俄文字母、汉语拼音符号、汉语注音字母,共 7445 个图形字符。
字符编码:把字符集中的字符编码为(映射)指定集合中的某一对象(例如:比特模式、自然数序列、电脉冲),以便文本在计算机中存储和通过通信网络的传递。
字符集和字符编码的关系 字符集是书写系统字母与符号的集合,而字符编码则是将字符映射为一特定的字节或字节序列,是一种规则。通常特定的字符集采用特定的编码方式(即一种字符集对应一种字符编码(例如:ASCII、IOS-8859-1、GB2312、GBK都是即表示了字符集又表示了对应的字符编码,但Unicode不是,它采用现代的模型)),因此基本上可以将两者视为同义词。
ASCII
1960年的时候,美国首先制定了ASCII编码,它主要是为了统一英文字符的表示,解决早期设备间通信的乱码问题。它仅支持基础的英语,键盘上的东西基本都可以表示了。
这个字符集对于程序员再熟悉不过了,尤其是底层开发的程序,而对于很多半道出家,在某嵌培训的Android初级程序员来说就不一定很熟悉。
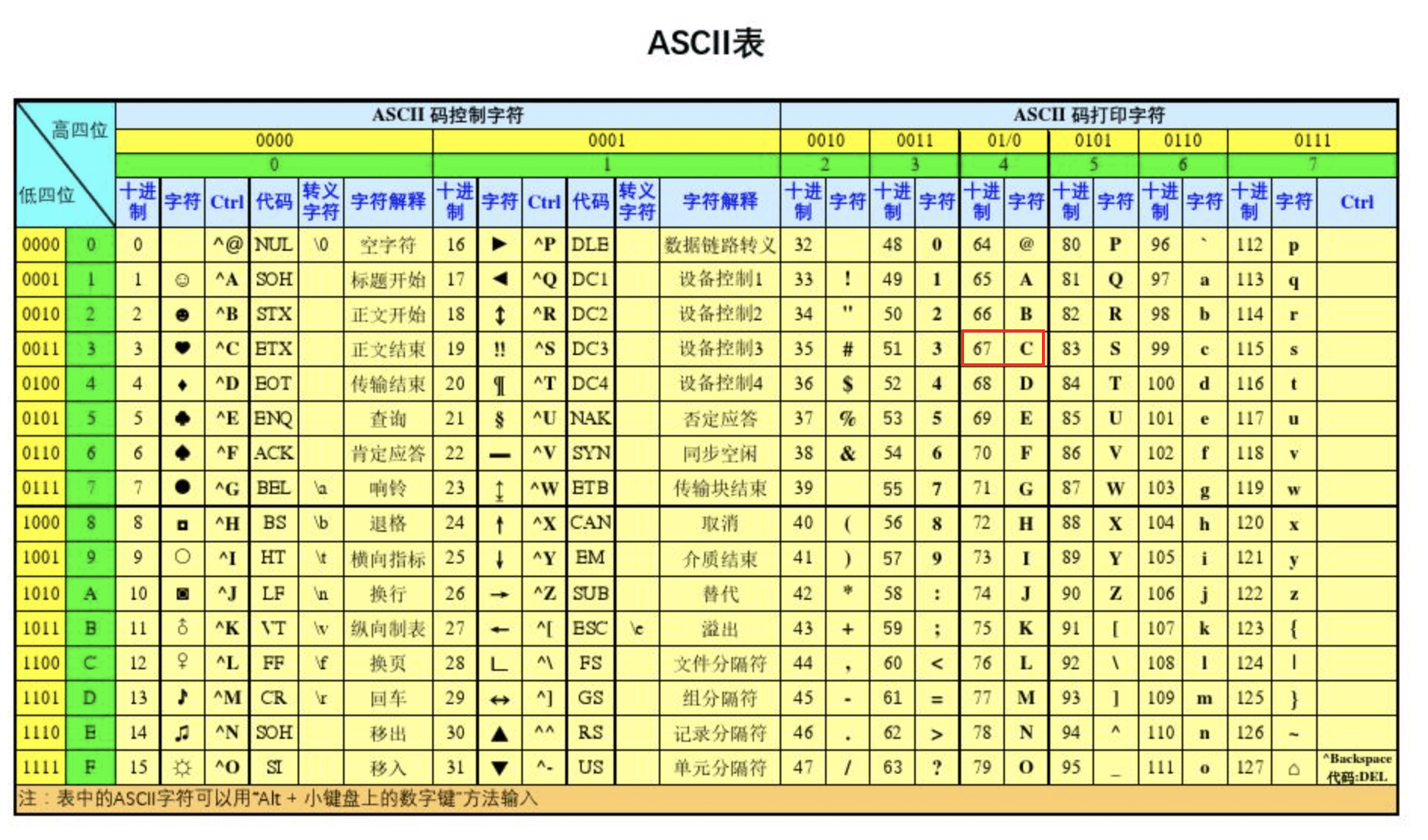
ASCII的编码规范是每个字符占用一个字节,实际上他只占用了0x00到0x7F的编码位置。
GB2312
对于GB2312编码,一看便知道使我们国家制定的,1980年,中国发布了首个针对简体中文的编码标准。目的就是为了解决ASCII无法处理中文的问题,让中国人能够用上电脑。
GB2312的字符集采用双字节编码,编码范围0xA1A1 – 0xF7FE。这对于搞液晶屏显示的同学再熟悉不过来,点阵字库就需要这个编码做索引。
这套编码包含了特殊符号,汉字,拼音,笔画部首等。
为了兼容ASCII码,规定每个字节的首bit位固定为1(当程序读取一个字节时:如果最高位为 0,则认为是 ASCII 字符。如果最高位为 1,则认为是 GB2312 字符的一部分(需要再读取下一个字节,组合成双字节字符))。这样也避免和ASCII冲突。
GBK
GBK是1995年发布的非强制标准,但是被window 95/98广泛采用,其主要目的是扩展GB2312,兼容了繁体字和生僻字。主要应用繁体中文游戏和网页。
GBK的理论空间是126*190,实际收录了21886个字符,包含日韩汉字,标点注音等。
GBK的编码规范中,首字节0x81 – 0xFE 兼容GB2312的0xA1 – 0xF7 。次字节0x40-0x7E和0x80-0xFE(移除GB2312次字节的”首bit为1″限制),完全兼容了GB2312和ASCII 。
GB18030
2000年发布的中国强制性国家标准,支持了多民族语言,全面兼容了Unicode编码,满足国际化需求。
GB18030的主要特点是变长编码:
- 单字节(0x00-0x7F):完全兼容ASCII
- 双字节(0x81-0xFE + 0x30-0x39):覆盖GBK字符
- 四字节(0x81-0xFE + 0x30-0x39 + 0x81-0xFE + 0x30-0x39):扩展支持Unicode全字符集
- 兼容性:兼容GBK、GB2312、ASCII和Unicode
Unicode
Unicode编码最早是1991年发布的,目的是想终结编码割裂问题,想让全球使用统一的编码集和编码格式。
其编码方案是变长编码
UTF-8:变长1-4字节,兼容ASCII,互联网占比超97%(2023统计),适合网络传输(如”汉”→E6B189)
UTF-16:2或4字节(代理对),Java/C#内部存储格式(如”汉”→6C49)
UTF-32:定长4字节,空间效率低但处理简单,用于内存对齐场景(如”汉”→00006C49)
篇外:为什么乱码是问号不是其他符号呢?
最开始出现的是 ASCII码、是美国人发明的,他将因为字母和特殊符号全部编码进去、采用了一个字节256种情况去编码这些字符
后来欧洲人看美国人整了个编码,于是自己整了个ISO-8859-1,他是为了将欧洲所有国家的语言文字全部编码进去,采用了 2个字节 65536种情况去对ASCII进行拓展,拓展完成之后,发现在码表中出现了大量的空白。也就是说有码值但是没有对应的字符。
后来中国人发明了GB2312,也采用了2个字节, 收录 6763 个汉字,
再后来GB2312 扩展成了GBK, 21886 个汉字和图形符号。
但也出现了大量空白的情况、当我们在解码一个字符的时候,如果编码和解码不一致的话很有可能造成读取的码值在码表中没有对应的字符,所以就用�代替。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
没有相关内容!

暂无评论...