最近听说 GD 的 M7 内核的 MCU 已经可以小批供货了,国产器件中总算又多了一个可以把玩的东西,必须得抽点时间来研究研究。

这款 M7内核的 MCU 有三个系列:GD32H737/757/759,本质上就是封装和存储资源的差异,毕竟芯片里面这两样成本占比比较重。
今天,轩哥并不是想聊 GD32H7,而是想学习一下针对于 M7 内核的 MCU,有哪些需要关注的点,以及有哪些编程上可以优化的点。
一、H7 的特点
首先看看 M7 内核的 GD32H7都具备哪些不一样的功能,以下只是我个人关注的点:
- 主频高,GD32H7系列MCU采用基于Armv7E-M架构,主频高达600MHz。
- 6 级流水线,并且是超标量的,并且支持分支预测。
- 内置了高级DSP硬件加速器和双精度浮点单元(FPU),以及硬件三角函数加速器(TMU)和滤波算法加速器(FAC)。
- 内置了TFT LCD液晶驱动器和图形处理加速器IPA (Image Processing Accelerator), 支持2D图像叠加、旋转、缩放及多种颜色格式转换等功能。
主频越来越高自然不必说了,后面两个内置硬件过两天在学习。
今儿先学习下 M7 内核的功劳,也就是这里的分支预测和超标量流水线。
二、什么是超标量流水线
超标量流水线(Superscalar Pipeline)是一种计算机处理器架构,它可以同时执行多条指令,从而提高指令执行的效率。这种架构允许处理器在一个时钟周期内执行多个指令,而不是像传统的标量流水线那样每个时钟周期执行一条指令。
先看传统的流水线架构:

在传统的标量流水线架构中,我们如果想让 CPU 执行一条机器指令,要经历:取址(IF)→ 译码(ID)→ 执行(EX)→ 访问内存(MEM)→ 写回内存(WB)等五个步骤,那么在系统时钟的驱动下,如果串行处理,那么执行一条指令至少要 5 个时钟周期。
CPU 在执行每一个单一步骤的时候,并不一定会用到所有的硬件,也就是说五个步骤其实存在一定的独立性,那么我们可以增加一些硬件让 CPU 在一个时钟触发下做两件以上的事情。
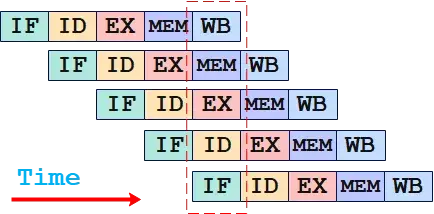
这么一来,我们就可以让多条指令的执行看起来并行执行,其实就是为每条指令的执行提前做一些准备工作,从结果看,我们几乎可以做到每个时钟周期执行一条指令了。
以上就是标量的流水线,就是让 指令执行进行一定的硬件分工,然后在一个时钟触发下,不同的硬件可以同时做一些不同的事情,从而保证每个时钟周期内都有一个产出 —— 执行完一条完整的指令。
OK,如果我想给让CPU 提高点人效,让它一个机器时钟内完成多个指令的执行该怎么办呢?
加人呗,一个岗位上放俩人,甚至更多🐶
当然人多了,容易乱套,这里是因为每个指令本质是上串行的,前后有依赖,所以不能一味的增加人力,结果肯定是流水线上打起来。
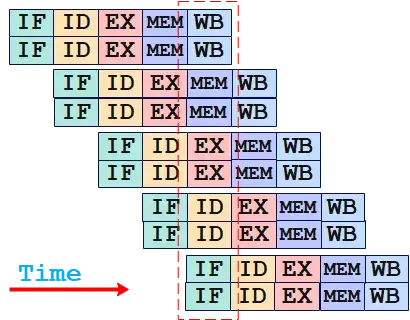
上图中,我们在每一个流水阶段增加了一个人力,整个系统看起来瞬间效率提高了一倍。
以上就是超标量流水线的描述,下面我们看看,如何在 程序设计上利用这个超标量的流水线。
三、如何利用超标量流水线
我们拿一个算法的代码实现来举例子,首先我们写一个求阶乘的子函数,这里我偷懒让 ChatGPT 帮忙生成了一个:
#include <stdio.h>
// 阶乘函数
int factorial_iterative(int n)
{
int result = 1; // 从1乘到n
for (int i = 1; i <= n; ++i)
{
result *= i;
}
return result;
}
// 示例
int main()
{
int result_iterative = factorial_iterative(5);
printf("5的阶乘是: %d\n", result_iterative);
return 0;
}这种简单的迭代算法的优点是比较容易理解,一眼就可以看出程序员想干什么。
但这样写出来的程序缺点也很大,就是运行效率非常低,我们在算法编写中最怕的就是for 循环,因为这里面会存在大量的比较和跳转,同时最容易产生一些代码被无效的循环执行。
这些缺点有的会被编译器的优化措施给规避掉,比如编译器可以把一些需要内存访问的变量先放到寄存器中,等计算完结果后,再把结果从寄存器中转移到内存中,因为 CPU 读取寄存器比读取内存可快多了。
但是编译器也不是万能的,有些优化他就做不到。比如,我们改成下面展开的样子,超标量的流水线就开始起作用了。
// 阶乘函数
int factorial_iterative(int n) {
int result0 = 1, result1 = 1, result2 = 1,result3 = 1;
// 从1乘到n
for (int i = 1; i < n; i += 4) {
result0 *= i;
result1 *= i + 1;
result2 *= i + 2;
result3 *= i + 3;
}
return (result0 * result1 * result2 * result3);
}首先,我们假设开启了编译器优化,编译器已经把所有内存访问的变量在函数开始都归置到了寄存器中,那么这时候我们可以看到,4 个 result 的乘法语句是相互独立的,他们的计算过程不依赖于其他 3 个语句的计算结果。

这就好比安排了四个人,给他们算 4 个单独的式子,假设他们计算能力相同,于是他们会在同一段时间后跑到黑板上来互相乘一下算个总的结果。
而如果我们只是简单的做循环展开,不增加新的寄存器变量,也就是不加人的情况下是怎么样的呢?
// 阶乘函数
int factorial_iterative(int n) {
int result = 1;
// 从1乘到n
for (int i = 1; i < n; i += 4) {
result *= i;
result *= i + 1;
result *= i + 2;
result *= i + 3;
}
return (result * result * result * result);
}这里只放了一个聪明的孩子做算式,不过你看他要做的 4 个算式,其中后一个算式总要用到前一个算式的结果,他即便再聪明也得一个一个的算。
这就是超标量流水线的用处,当然展开多少还需要我们自己衡量,本质上也是用空间换时间,另外寄存器可是稀缺资源。
四、什么是分支预测
在超标量的流水线架构上,我们得知,CPU 在运行指令的时候,会在一个时钟上做多个操作,也就是涉及到调用前后相关的指令,比如我们在一个简单的判断语句中。
if(n > 0)
{
n = 5;
}
else
{
n = -5;
}在执行 if 语句的时候,一定会对判断语句执行结果后的下一条语句进行取址和译码,那么在还没有判断结果之前应该对哪一个语句进行取址呢?这就是分支预测要解决的问题。

简单说,分支预测就像我们铁路分叉口上的操作员,操作员在没有看到火车上面的转向旗帜的情况下,到底应该往哪边搬动扳手呢?对于 CPU 来说,他做不到铁路系统中的提前通信告知,因此他只能根据历史来进行推测,提前做选择,如果选择错了,咱就让列车停下,倒回来,重新开。因此,分支预测会出现预测失败的情况,而失败后的回滚操作非常占用时间,所以我们需要避免分支预测失败概率过大,或者说是把具有分支预测失败情况的判断放到循环内部,让失败回滚多次循环。
五、应对分支预测有哪些优化措施
下面再来看一下分支预测,这也是 ChatGPT 给出的一个简易答案
// 不利于流水线的循环结构
for (int i = 0; i < N; ++i) {
if (condition) {
// 循环体
}
}
// 更有利于流水线的循环结构
if (condition) {
for (int i = 0; i < N; ++i) {
// 循环体
}
}上面的案例就是说明,我们应该在循还外进行条件判断,这样即便是预测失败概率 10%,也只有 10%的回滚情况,但是如果放到循环体内部,那么这个 10%的回滚操作将被执行 N 次。除了把判断语句从循环体中挪出来,还有一些小的技巧供大家参考一下。
合并条件,尽可能减少分支预测失败时对效率的影响
优化前:
if(case1)
{
if( case2 )
{
do();
}
}优化后:
if( case1 && case2 )
{
do();
}优化前:
if( case1 == 0 && case2 == 0 && case3 == 0 )
{
do();
}优化后:
if( ( case1 | case2 | case3 ) == 0 )
{
do();
}跳转避免分支预测
将if else改写成switch形式(switch使用的指针 list 进行跳转的指令,直接跳转到对应分支)。这样就相当于将多个函数使用函数指针的形式存储到数组中,然后通过 case 查表,直接进行调用。
直接运算,避免判断
先说明一些基本位运算知识:
|x| >> 31 = 0 // 非负数右移31为一定为0
~(|x| >> 31) = -1 // 0取反为-1
-|x| >> 31 = -1 // 负数右移31为一定为0xffff = -1
~(-|x| >> 31) = 0 // -1取反为0
-1 = 0xffff
-1 & x = x // 以-1为mask和任何数求与,值不变如对于
if(value < 0 ) value = 0可改成
value &= ~(value >> 31 )再比如:
if (data[c] >= 128)
{
sum += data[c];
}可以优化为:
int t = (data[c] - 128) >> 31; // 非负数右移 31 为 0,负数右移则为 -1
sum += ~t & data[c]; // 这里利用 0 和 -1,正好等同于条件,大于 128 忽略,小于 128 累加。
更多的位运算知识可以查看下面的网址 Bit Twiddling Hacks
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
没有相关内容!

暂无评论...